So the INSPIRE Conference 2014 (#inspire_eu2014) starts tomorrow - after two days of intensive workshops.
For me this poses the challenge to decide which of the parallel sessions I should attend to. As I have been experimenting with the R framework lately I decided to make use of some text mining techniques instead of reading through all the abstracts to get an idea about hot topics, trends and potentially interesting sessions.
Here are some of my 'results'. More on the methodology below.
To get a first impression I take a look at terms that appear frequently (15+) in the contribution's titles:



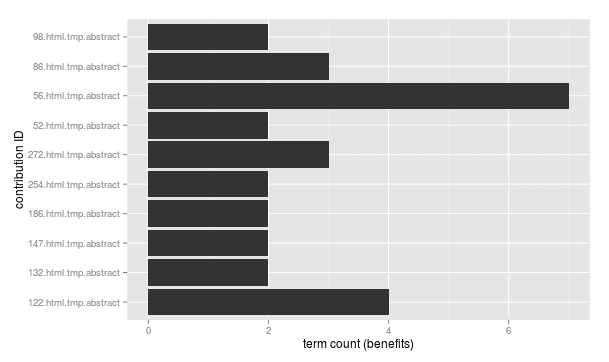


http://inspire.ec.europa.eu/events/conferences/inspire_2014/schedule/submissions/<ID>.html
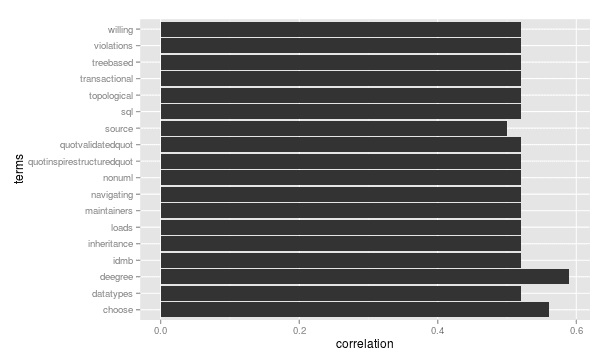
Besides that the tm-package offers a lot of functionality to analyse the datasets further. For example I can identify terms that are correlated to a specific term. For instance terms that are correlated (0.5+) with "wfs" (considering all abstracs) are:
So a few words on what I did.
Getting ready:
- download the abstracts (wget)
- removing headlines, html, blank lines, line breaks (sed, tr)
- extracting abstracts, titles (sed)
- convert all characters to lower-case
- remove numbers, punctuation, whitespaces
- remove URLs
- remove stopwords
- apply word stemming
- apply stemcompletion
Follow @spatialbits